Polychoric correlation using a bayesian framework in Stan.
Published
January 1, 2023
Motivation: It’s likely likert
Look at you, you successful businessperson you! You own a company that sells two products: A and B. You run a short two question survey to determine whether your customers would recommend either products. For this example we’ll assume that all customers are using both products. The question style is the commonly used “Net Promoter Score” or likert scale format:
“Provide your level of agreement to the following question: I would recommend this product to a friend”
Where the available choices are:
Strongly Disagree
Somewhat Disagree
Neither Agree or Disagree
Somewhat Agree
Strongly Agree
There are of course limitations to this kind of survey design. For one, most people have a hard time discretizing their feelings or emotions into a single bucket. Perhaps the more appropriate question response would feature a slider that allows respondents to freely select their agreement on a continuous scale. Regardless, as this is the design chosen by thousands of companies and organizations, we’ll choose it as well. Though, we’ll recognize that agreement or sentiment in general is better categorized as a spectrum.
Enough philosophy, now to the actual data. I’m going to show how the data is generated further down, but for now let’s say that we ran the survey and collected 1,000 responses. First, let’s start by loading in all the packages we’ll need for this analysis.
Next, we’ll take our discrete_data data frame which holds our survey responses and visualize it as a table of all unique responses. For example, the third row and second column will be the number of customers that responded 3 to question 1 and 2 to question 2.
From the table above, we can already see that there is a high degree of positive correlation between the questions. If we wanted to quantifying this correlation, we might naively use the cor function, but this produces biased results as our provided data is not continuous, which is assumed by the default Pearson correlation measure. There are other measures of correlation such as Spearman or Kendall which are non-parametric, but neither take into account the data generating process that aligns with our philosophy. For that, we will need to employ the polychoric correlation which we will further define below.
Data Generating Process
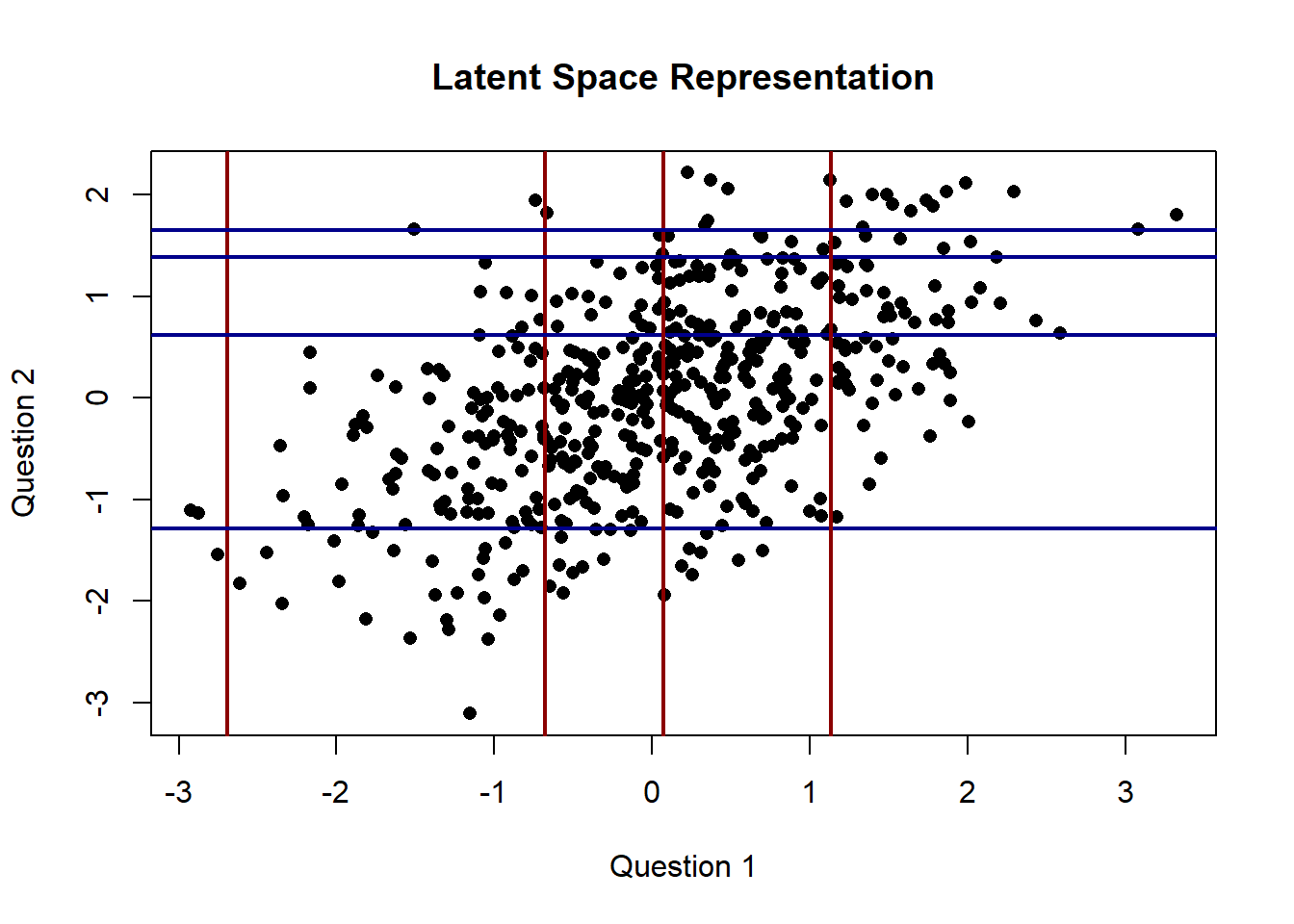
We assumed that our data was generated by customers that were forced to discretize their agreement with a given question. If we wanted to properly model this, we might want to assume that our data is first generated from some latent multivariate continuous distribution, and then discretized using a set of p - 1 “cut-points” for each dimension of the latent space, where p is the number of possible choices in the questionnaire. The code to generate data from this process is shown below:
Our model is almost fully specified with the data generating process outlined above, but we still need to incorporate our priors. For the correlation matrix, we will reparametrize using the Cholesky decomposition and use a LKJ prior. The cut-points are a little trickier, but notice that the marginals of our latent distribution are standard normals. We can use this to our advantage by reparametrizing the cut-points as a vector of probabilities where each entry is the probability allocated to the interval on the standard normal distribution between two adjacent cut-points \(c_i\) and \(c_j\). Note that for \(p-1\) cutpoints, there will be \(p\) entries in our probability vector. Thus, we can write:
\[
\begin{align}
\begin{bmatrix}
c_1\\
c_2 \\
\vdots\\
c_{p-1}
\end{bmatrix}
& \rightarrow \begin{bmatrix}
\theta_1\\
\theta_2\\
\vdots\\
\theta_{p}
\end{bmatrix} \\ \\
&= \begin{bmatrix}
\Phi(c_1) \\
\Phi(c_2) - \Phi(c_1) ] \\
\vdots \\
1 - \Phi(c_{p-1})
\end{bmatrix}
\end{align}
\] Since our probability interval vector must sum to one, we can use a dirichlet distribution as the prior. The stan code to specify this prior and perform the reparametrization is below:
The stan code is a bit more involved, and includes the Jacobian calculations since we are specifying a prior on the transformed parameters. For more detail about the reparametrization and Jacobian calculations I suggest reading Michael Betancourt’s ordinal regression tutorial. Be aware that his model uses a latent logistic distribution (different than our standard normal).
Finally, we need to consider the likelihood of the data, conditioned on our parameters. To model this, we will extend the multivariate probit model to the case where an arbitrary number of ordinal categories are observed. Without going into too much detail, the multivariate probit is used to model a bernoulli distributed random vector, where the data is assumed to have been generated from a latent multivariate normal distribution. For example, if you consider our data generating process above but instead only have one cut-point per dimension, then the data generated would be a bernoulli random vector. The stan code used to define this extenstion of the multivariate probit likelihood is here, along with the full stan code for the model.
The full derivation for the likelihood, and therefore stan code, is beyond the scope of this blog post, but I refer you to these two other resources to learn more if you are interested:
The parameters of interest here are L_Omega, which will give us the correlation matrix for our latent gaussian and the c_points array which determines the cut-points that generated our data. Ignore the u parameter, as it is a nuisance parameter and is only used to help define the likelihood of our data.
Sampling and Posterior Exploration
Now that are model is fully defined, we can used the cmdstanr package to sample our posterior. The full stan code can found here. Note, during model fitting we are expecting some rejected samples due to the highly constrained values of the correlation matrix. When fitting this model with a higher dimension latent
# fp <- file.path('PATH TO YOUR STAN MODEL CODE')mod <-cmdstan_model(fp)data <-list(D =ncol(discrete_data),N =nrow(discrete_data),y = discrete_data,y_min =min(discrete_data),y_max =max(discrete_data))poly_cor <- mod$sample(data = data, seed =1234, chains =4, parallel_chains =2,iter_warmup =2000,iter_sampling =2000)
Let’s take a look out some diagnotics to make sure we had adequate posterior sampling:
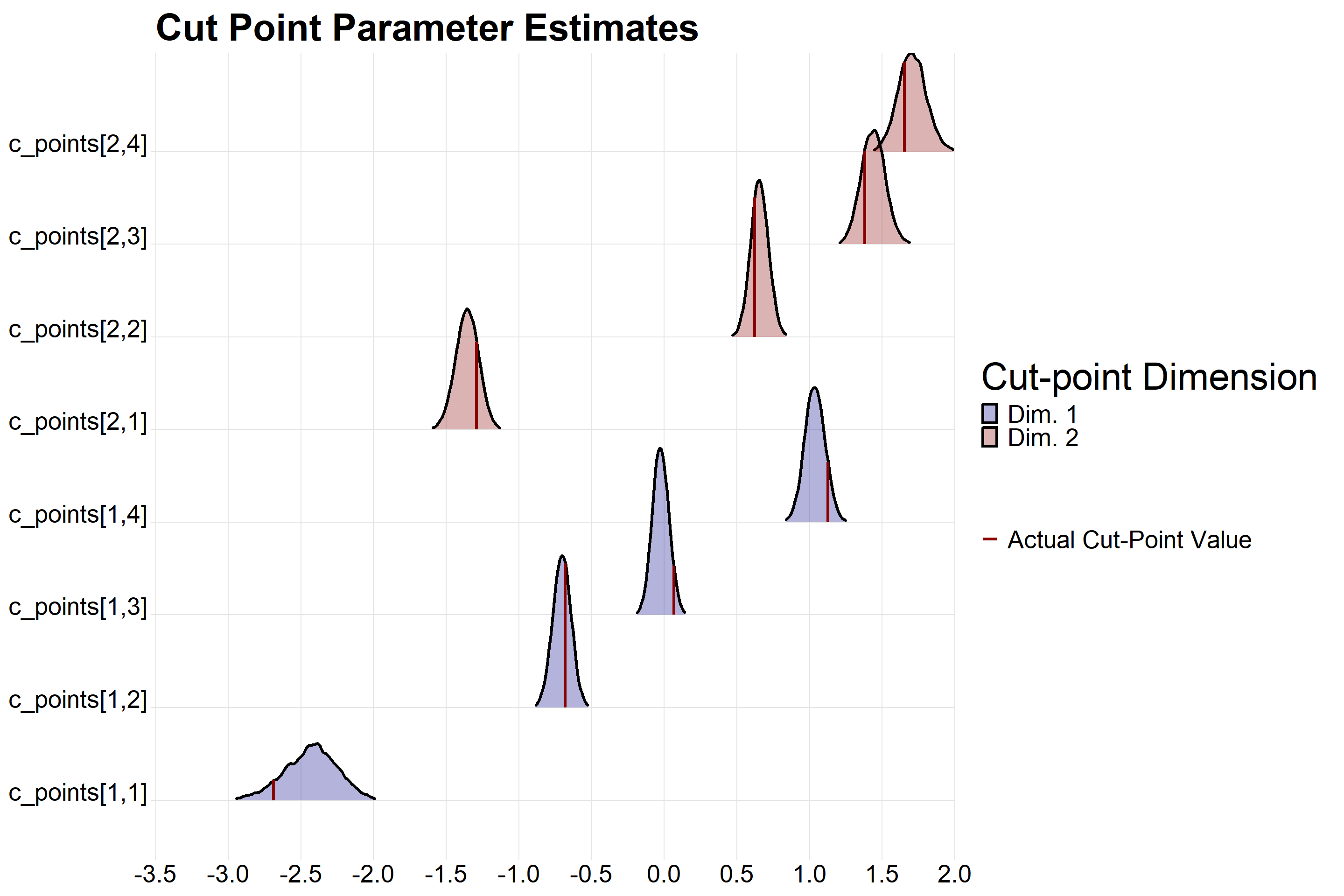
Our Rhat, ess_bulk, and ess_tail look good! Let’s take a look at our posteriors for the c_points parameter. The ggplot code that adds line segments to the ridge plot is adapted from this stackoverflow post.
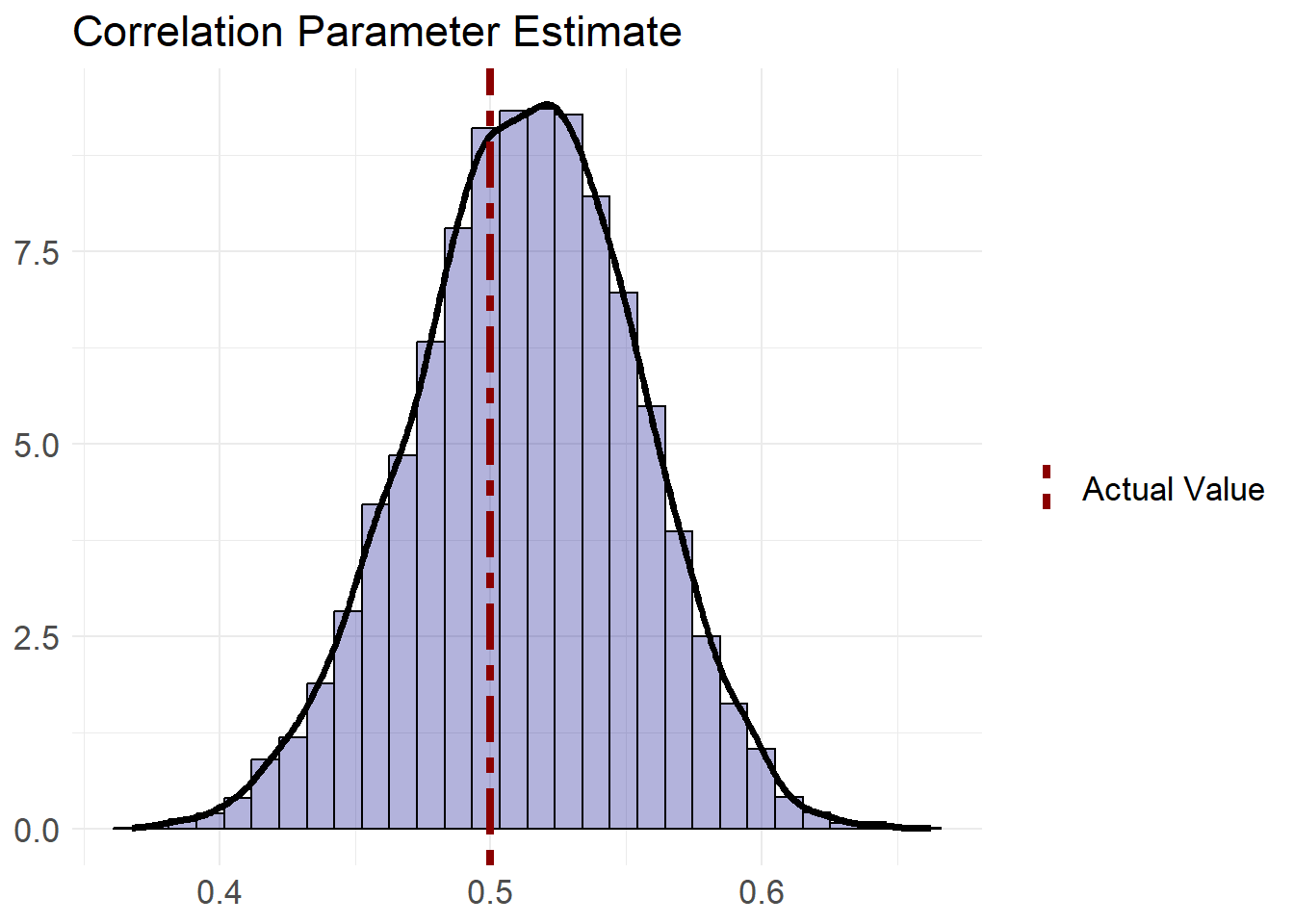
It looks like the actual value of each cut-point is captured within the range of each estimated parameter. Now we can look at our originally requested quantity; the correlation.
It looks like our model fits the data well and is able to adequately identify the parameters. While the polychoric correlation is a little more involved than a simple pearson correlation, it aligns more with our original data generating process philosophy. Since this model was fit using a bayesian framework we have samples from our posterior which we can use to perform decision analysis, generating pseudocustomers, or probabilistic PCA from the posterior of the correlation matrix.