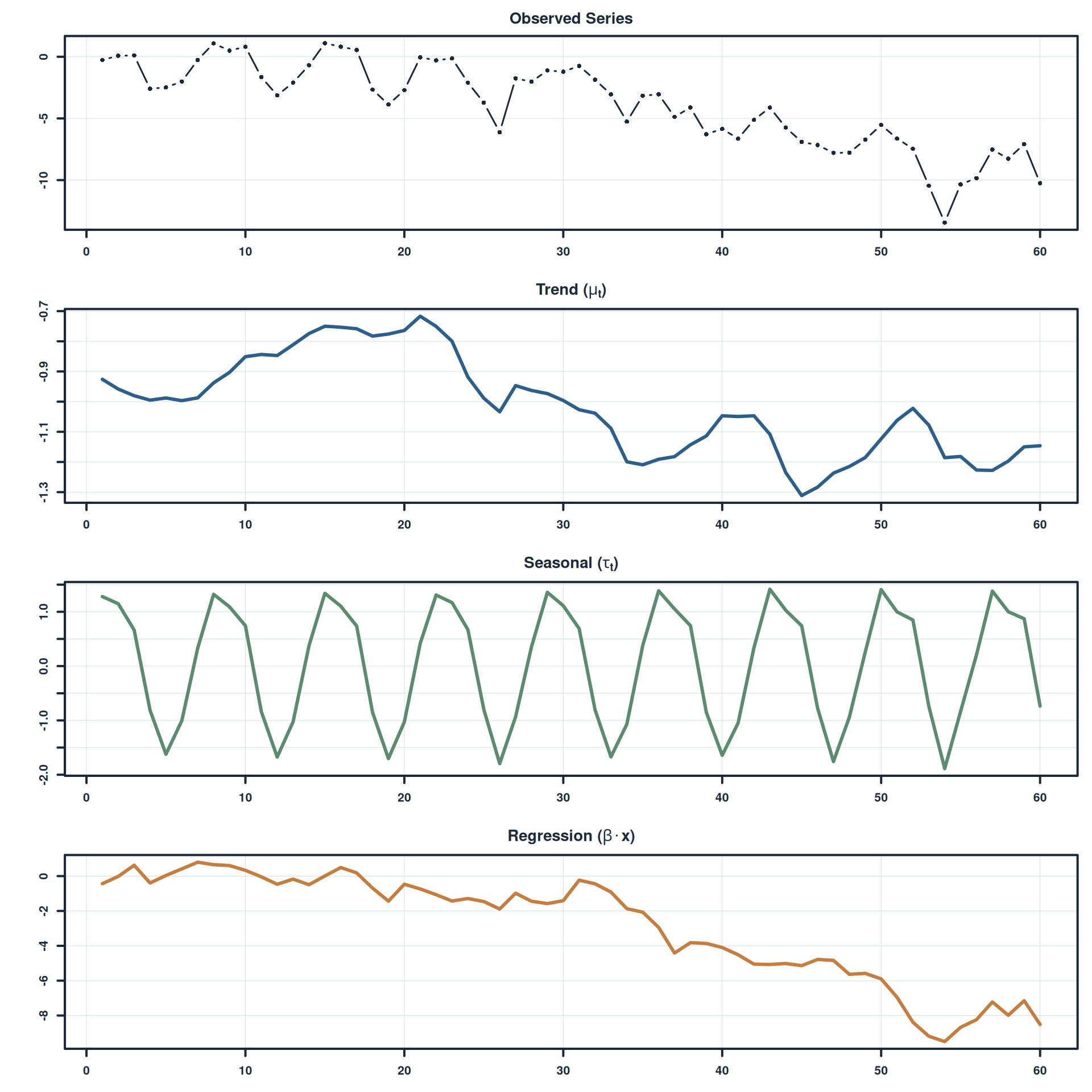
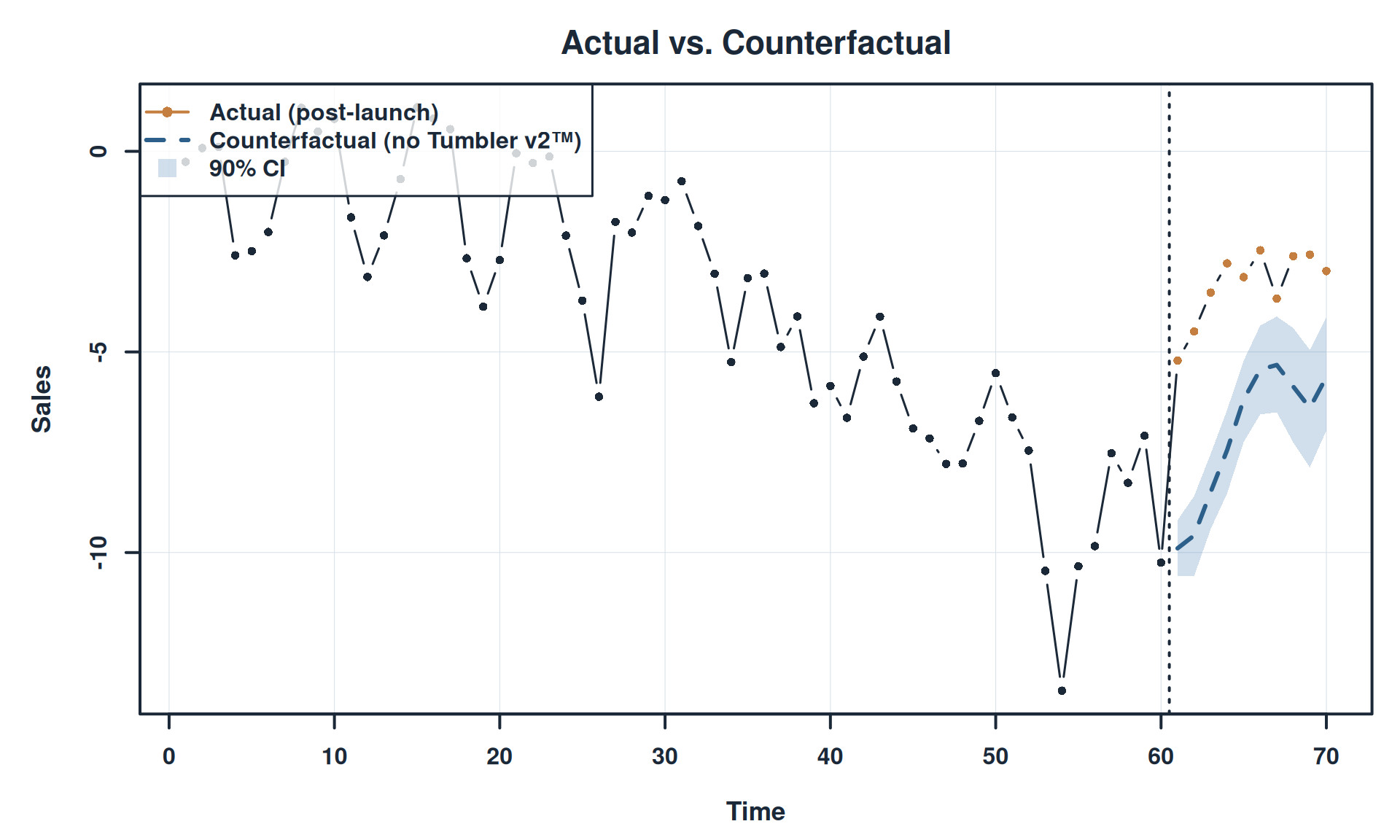
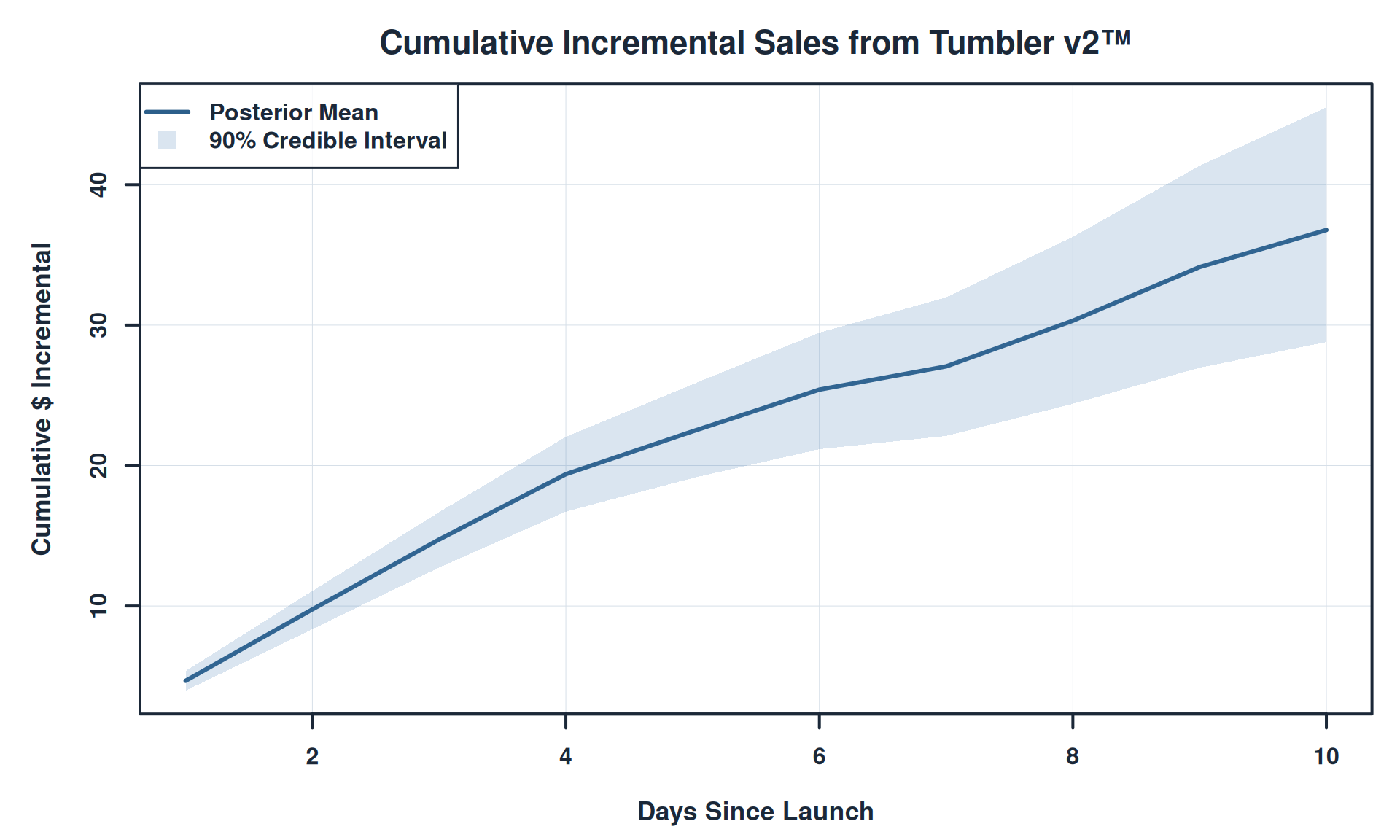
# Plot
par(mar=c(4.5, 5, 3, 1), family='sans')
x_idx <- (n_pre + 1):(n_pre + n_post)
plot(seq_along(y_vec), y_vec, type='b', pch=16, cex=0.8, lwd=1.5,
main='', xlab='', ylab='',
col=ifelse(is_new_prod_live, pal$copper, pal$navy),
axes=FALSE, panel.first=grid(col=pal$grid, lty=1, lwd=0.5))
title(main='Actual vs. Counterfactual', font.main=2, cex.main=1.4, col.main=pal$navy)
title(xlab='Time', ylab='Sales', font.lab=2, cex.lab=1.1, col.lab=pal$navy)
axis(1, lwd=2, col=pal$navy, col.axis=pal$navy, font=2)
axis(2, lwd=2, col=pal$navy, col.axis=pal$navy, font=2)
# Counterfactual with uncertainty
cf_mean <- colMeans(counterfactual)
cf_q05 <- apply(counterfactual, 2, quantile, 0.05)
cf_q95 <- apply(counterfactual, 2, quantile, 0.95)
polygon(c(x_idx, rev(x_idx)), c(cf_q05, rev(cf_q95)),
col=adjustcolor(pal$slate, 0.25), border=NA)
lines(x_idx, cf_mean, lwd=3, col=pal$blue, lty=2)
abline(v = n_pre + 0.5, lwd=2, lty=3, col=pal$navy)
legend('topleft',
legend=c('Actual (post-launch)', 'Counterfactual (no Tumbler v2\u2122)', '90% CI'),
col=c(pal$copper, pal$blue, NA), lwd=c(2,3,NA), lty=c(1,2,NA),
pch=c(16, NA, 22), pt.bg=c(NA, NA, adjustcolor(pal$slate, 0.25)),
pt.cex=c(1, 1, 2), text.font=2, text.col=pal$navy,
bg=adjustcolor('white', 0.8), box.lwd=1.5, box.col=pal$navy)
box(lwd=2, col=pal$navy)